-1.png)
はじめに
最新のAIの進展、特に大規模言語モデル(LLM)はChatGPTをはじめ、広く認知がされてきています。それと同時に、これらの大規模DNNモデルは電気を大量に使用することから、環境への影響なども問題視されており、この課題についても広く一般層までに広まっている様に感じます。
この課題を解決する可能があり、注目されているのがBitNetです。この記事では、BitNetとは何か、その重要性、そしてその動作原理について初心者にもわかりやすく解説します。
従来のDNNモデルの重みとは?
従来のディープニューラルネットワーク(DNN)モデルでは、重み(パラメータ)は通常、16ビットの浮動小数点数(FP16)で表されます。これらの重みは、モデルがトレーニングデータから学習するパラメータであり、非常に高い精度で計算されます。しかし、この高精度な計算には多くのエネルギーとメモリが必要です。具体的には、モデルのトレーニングと推論時に大量の浮動小数点演算が行われ、それが計算コストとエネルギー消費を引き上げる要因となっています。
BitNetの重みとは?
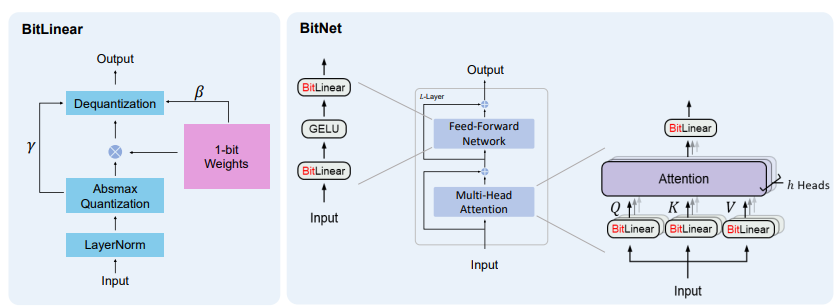
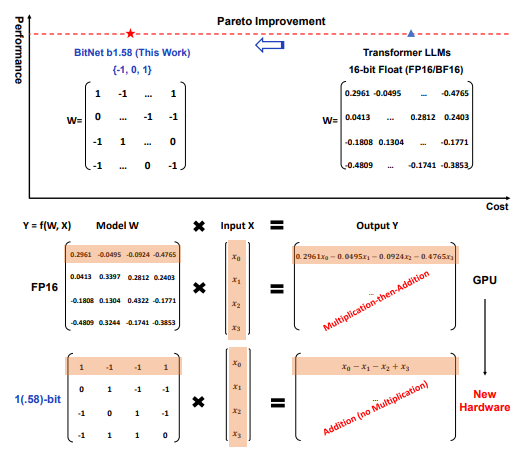
これに対して、BitNetは重みを1.58ビットの三値(-1、0、1)で表します。これは量子化と呼ばれるプロセスで実現され、計算の精度を維持しながらも必要なリソースを大幅に削減します。具体的には、以下のような特徴があります:
- 量子化: BitNetは重み(モデルが学習するパラメータ)を1.58ビットの値、具体的には-1、0、または1に変換します。これにより、浮動小数点演算が不要になり、整数の加算のみで計算が行われます。
- 効率性: この三値重みによって、計算資源の消費が大幅に減少し、エネルギー効率が向上します。
BitNetの重要性とは?
大規模言語モデルは、人間のようなテキストを理解し生成する驚異的な能力を持っていますが、高いコストがかかります。大量の計算力とエネルギーを必要とするため、運用コストが高く、環境にも優しくありません。BitNetは以下の方法でこれらの課題に対応します:
- エネルギー消費の削減。
- メモリ要件の低減。
- 高いパフォーマンスの維持。
BitNetの仕組みは?
- 量子化: BitNetは重み(モデルが学習するパラメータ)を1.58ビットの値、具体的には-1、0、または1に変換します。これは量子化というプロセスで行われます。
- 行列の乗算: 従来のモデルが浮動小数点演算を使用するのに対し、BitNetは整数の加算を使用します。これによりエネルギー消費が大幅に削減されます。
- 効率性: 計算の精度を下げることで、BitNetは処理速度を速め、メモリ使用量を削減します。
MNISTデータセットでのBitNetの精度:
BitNetの有効性を示すために、MNISTデータセットでの実験が行われています。MNISTは手書きの数字(0-9)の画像データセットで、画像認識モデルの評価に広く使用されています。BitNetを使用した実験では、1.58ビットの重みでありながら、精度を高く保つことができています。この実験により、BitNetが従来の16ビットモデルと同等の精度を達成しつつ、計算コストとエネルギー消費を大幅に削減できることが示されています。


実際の応用例:
BitNetは、以下のような大規模言語モデルが役立つさまざまなアプリケーションで使用できます:
- 自然言語処理(NLP): 翻訳、要約、感情分析などのタスク。
- チャットボット: より効率的でコスト効果の高いAI駆動のカスタマーサービス。
- エッジデバイス: スマートフォンやIoTデバイスなど、計算能力が限られているデバイスでの高度なモデルの実行。
まとめ:
BitNetは、大規模言語モデルをよりアクセスしやすく、持続可能なものにするための重要な一歩を示しています。計算とエネルギーのコストを削減しながら高いパフォーマンスを維持することで、BitNetは日常の技術におけるAIの新しい可能性を開きます。
参考文献:
- Hongyu Wangらによる論文「BitNet: Scaling 1-bit Transformers for Large Language Models」を参照してください。この論文はこちらでアクセスできます。
- BitNetの技術的な詳細については、Shuming Maらによる論文「The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits」を参照してください。この論文はこちらでアクセスできます。
- MNISTデータセットでのBitNetの実験詳細については、こちらのブログを参照してください。

コメント